
A Review of Deep Learning-based Multi-modal Medical Image Fusion
Authors Info & Affiliations
Abstract
Introduction
Medical image fusion combines the data obtained from different imaging modalities such as Computed Tomography (CT), Positron Emission Tomography (PET), and Magnetic Resonance Imaging (MRI) into a single, informative image that aids clinicians in diagnosis and treatment planning. No single imaging modality can provide complete information on its own. This has led to the emergence of a research field focused on integrating data from multiple modalities to maximize information in a single, unified representation.
Methods
CNN (Convolutional Neural Network) was applied to achieve robust and effective multi-modal image fusion. By delving into the principles and practical applications of this deep learning approach, the paper also provides a comparative analysis of CNN-based results with other conventional fusion techniques.
Results
CNN-based image fusion delivers far better results in terms of qualitative and quantitative analysis when compared with other conventional fusion methods. The paper also discusses future perspectives, emphasizing advancements in deep learning that could drive the evolution of CNN-based fusion and enhance its effectiveness in medical imaging.
Discussion
CNN-based multi-modal medical image fusion proves strong advantages over traditional methods in terms of feature preservation and adaptability. However, challenges such as data dependency, computational complexity, and generalization across modalities persist. Emerging trends like attention mechanisms and transformer models show promise in addressing these gaps. Future work should focus on improving interpretability and clinical applicability, ensuring that deep learning fusion methods can be reliably integrated into real-world diagnostic systems.
Conclusion
Ultimately, this work underscores the potential of CNN-based fusion to improve patient outcomes and shape the future of medical imaging by advancing the understanding of multi-modal fusion.
1. INTRODUCTION
In the last few years, multi-modal image fusion has become a much-favored approach in numerous application areas, including medical imaging, remote sensing, surveillance, and autonomous systems. Combining complementary information, fusion of images from several modalities gives a larger perspective of complicated situations. Here, as an example, in medical imaging, CT scans give structural details, MRI gives soft tissue contrast, and together offer images with better diagnostic value. Likewise, in remote sensing, multi–spectral images sample a group of different environmental attributes, a panchromatic image gives high resolution in spatial (spatial) details, and their fusion produces an image that retains both spectral and spatial information. There is no single modality that can give the complete diagnostic details. Therefore, fusion of medical images is preferred. Multi-modal image fusion is the concept of combining data from different imaging sources into a single informative output image to support better analysis and interpretation, and decision making [1]. Driven by improvements in artificial intelligence (specifically deep learning), the landscape of multi-modal image fusion has changed dramatically. Fusion methods in traditional frameworks are based on mathematical models and manual feature extraction methods such as wavelet transform, Principal Component Analysis (PCA) or other statistical approaches. However, the high complexity and variability of data from different modalities present significant limitations to the application of these methods. In contrast, deep learning-based fusion techniques can automatically learn elaborate features and patterns and are well-suited for multi-modal fusion tasks. Particularly, CNNs, Generative Adversarial Networks (GANs), and transformers lend themselves to this task, as they are capable of extracting complex features and relationships across different imaging modalities [2].
Deep learning provides one of the significant advantages for multi-modal image fusion. It can learn complex hierarchical representations automatically. Typically, traditional fusion methods rely on manual intervention to extract and select features, which is a time-consuming and error-prone effort. Whereas the process is, however, automated in deep learning in a data-driven way, both low-level and high-level features are learned. Although this capability could be useful in many domains, it is particularly important in domains such as medical imaging, where small differences between different modalities can mean big differences in terms of information. As an example, a well-trained deep learning model can bridge individual details of a modality in the fused output directly and maintain them, therefore, as it generates images that are richer in information and appropriate for diagnostic purposes [3]. With CNNs, deep learning models are flexible and can be trained for pixel-level, feature-level level and decision-level fusion. On the pixel level, fusion is of raw pixel information of each modality, whereas, in the feature level, fusion is of higher-level features extracted from convolutional layers. In contrast, decision-level fusion reflects the combination of decisions or interpretations of each modality. Because of this flexibility, deep learning models can be used for a variety of fusion tasks at both low levels as imaging and at high levels as interpretation [4]. The last advantage is that the deep learning-based fusion methods are scalable. Deep learning models can perform multispectral image processing quickly upon being trained, and this is valuable for real-time (or near real-time) processing in applications such as autonomous driving and surveillance. In addition, deep learning models can also frequently be fine-tuned for one use case and work well with other types of data or with new imaging conditions. Adaptability is extremely useful in fields such as remote sensing, where environmental conditions change rapidly, leading to a variety of input image quality and characteristics [5]. The example of multi-modal medical image fusion is shown in Fig. (1).
While deep learning based multi modal image fusion has many advantages, it also has a few distinct disadvantages. The big challenge is that a huge amount of labeled data is required to train. The effectiveness of the deep learning model based on CNN and GAN, etc, highly depends on a sufficient amount of data for training. In the medical imaging domain, for instance, collecting a multi-modal labeled dataset may be difficult for privacy reasons, limited access to high-quality data and labeling cost [6].
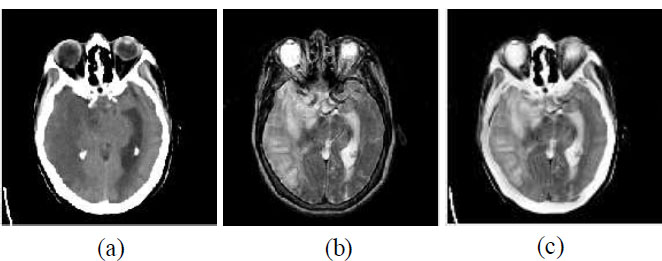
Example of multi-modal medical image fusion (a) Source image 1— CT image, (b) Source image 2— MRI image, and (c) Fused image.
The second point to be mentioned is that deep learning models are computationally intensive. Training a deep neural network, particularly one with many layers, is quite computationally expensive (on the order of high-performance GPUs or cloud-based computing). However, this computational demand limits easy accessibility of deep learning-based fusion for institutions or researchers with limited resources. Additionally, most deep learning models are treated as 'black boxes', meaning that the internal reasoning behind their decisions cannot be easily interpreted. This lack of transparency is a problem in fields such as medicine, where knowledge of the rationale for a fused image is often needed for clinical decision making. However, interpretability is an active limitation in deep learning-based methods, and researchers are hard at work on interpretability techniques right now [7]. A central challenge in this field is how to design fusion architectures capable of dealing with the heterogeneity of different modalities. The images are of different modalities with large differences in spatial resolution, intensity distribution and structural properties. For example, CT and MRI scans will show you different types of tissues and will have differing types of resolution. It is challenging to develop a deep learning model that can usefully integrate these diverse types of information into a single, coherent output. However, when misalignment and different resolutions are present in inputs, they can produce artifacts in the fused output if not handled [8].
As a result, developing and benchmarking the deep learning-based fusion models can be tricky and requires task-specific metrics [9]. As another significant challenge, model generalization still needs to be resolved. However, the robustness of these models is limited by their sensitivity to generalizing from specific datasets or imaging conditions [10]. For example, a model learned from Medical Images taken from a particular type of MRI machine may not work on Images acquired from a different machine or protocol. However, the lack of generalizability in this regard restricts the use of fusion models for real-world tasks in which variability of imaging conditions is common [11]. There are some persistent problems in the current deep learning-based image fusion. One such issue is that when some fusion techniques tend to produce overly smooth or blurred fused images, fine details get lost. For instance, when models seek to introduce spatial consistency at the expense of modality-specific information, the resulting fused image is poorly sampled, lacking sharpness and possibly containing clinically relevant information [12]. There is a problem with the limited interpretability of fused images. Deep learning models can create high-quality fused images, but the lack of interpretability of deep learning models makes it hard for practitioners to trust or adopt this approach. Medical practitioners may be reluctant to use fused images for diagnosis if they do not know how a fusion process has preserved or changed certain anatomical structures. There are a lot of investigations being conducted to make deep learning models more interpretable, but interpretability still stands as a roadblock for deeper adoption [13]. Furthermore, multimodal datasets require models that can accommodate temporal and spatial inconsistencies. In a dynamic scenario such as autonomous driving, images from different sensors (e.g., radar, LiDAR, camera) are taken at a slightly different time or from different viewpoints. However, due to this temporal and spatial discrepancy, it will cause challenges in fusion, the fused image can have artifacts or inconsistent areas that may harm the downstream tasks. Such problems are difficult for traditional fusion methods, and although deep learning can provide some answers, more research is needed to develop robust models that can deal with this in real time [14]. Another area of ongoing research is the further development of fusion models suitable for use with the varying quality of data. In practice, input images differ in quality from one image to another, e.g., low noise and good lighting conditions, low noise and low light conditions, etc. Automatic selection of fusion algorithms, however, is a task that has not been fully addressed before. Designing fusion algorithms that flexibly adjust their processing depending on the image quality of the input images is a challenging objective [15]. In conclusion, though the multi-modal image fusion is greatly promoted by deep learning, there are still many problems. They include data requirements, computational demands, model interpretability, issues concerning generalizability and robustness. To solve these struggles, further research and innovative work are needed, because deep learning presents one avenue to augment multi-modal image fusion and make it possible in real-world scenarios and various applications [16].
After the introduction, Section 2 briefly describes the theoretical foundations and importance of CNN-based multi-modal medical image fusion. Section 3 describes the results of CNN-based image fusion. Section 4 describes the step-by-step procedure of CNN-based image fusion, and this paper is concluded in Section 5.
2. MATERIALS AND METHODS
Medical imaging has soared in the wake of the introduction of a variety of imaging modalities like CT, MRI, PET, and ultrasound images. All modalities give unique insight into the body, collecting different information, anatomical or functional. If only one imaging modality is available, it is powerful, but it is usually limited to the type of information that it can capture. For example, MRI has great soft tissue contrast but poor bone detail, while CT scans give very good bone detail but are not contrasted in soft tissues. However, to overcome these limitations, multi-modal medical image fusion has been proposed to merge complementary information from multiple imaging modalities to generate a single enriched image. Over recent years, CNNs have become central in multi-modal medical image fusion, providing effective and sophisticated techniques to fuse images to maintain important details and improve the diagnostic accuracy [17].
2.1. Role of CNN-Based Multi-Modal Medical Image Fusion
CNN-based multi-modal medical image fusion plays an important role in combining multiple modalities to offer clinicians a richer insight into a patient’s anatomy and physiology. In comparison to more traditional fusion methods that rely on manually extracting features and fixed rules, CNNs learn the fusion task from data, deriving the relevant features, as well as the fusion, in a data-driven way. The ability to learn and adapt gained from CNNs makes them particularly well suited for medical applications where subtle differences in the images have a critical impact on the diagnosis [18].
CNN-based fusion is also used in other medical-related fields. For example, in oncology, where metabolic information from PET is fused with anatomical detail from MRI, to accurately localize tumors. CNNs can automatically fuse these modalities to provide a detailed image that can assist oncologists in their treatment planning and monitoring [19]. When using neuroimaging technologies and combining MRI and functional MRI (fMRI) via CNNs, neurologists can request an assessment of brain activity and structure from the same image, thus improving diagnostics of diseases such as epilepsy and Alzheimer’s disease. In addition, fusion of CT and MRI images in cardiovascular imaging enables examination of the structure and function of the heart, supporting the comprehensive cardiac evaluation [20].
2.2. Significance of CNN-Based Multi-Modal Medical Image Fusion
Since the fusion of high-resolution CNN-based images can offer accurate and high-resolution images employing both the anatomical and functional information with regard to diagnostics, it has become an important issue in the field of medical image fusion. Unlike the traditional flat layers which are used in the feedforward neural network, where it can learn from only predefined features, or merely surface textures, CNNs with deep layers and convolutional filters can learn from complex patterns and textures that exist in medical images and help with distinguishing important details from noise. Importantly, this capability allows to produce fused images that both visually and diagnostically inform with respect to medical conditions for improved interpretation by the physician [21]. One particularly interesting advantage of CNNs is the capability of doing pixel-level and feature-level fusion. In pixel-level fusion, information from each pixel in the source images is fused, preserving fine details, while in feature-level fusion, higher-level features are aggregated, which captures more abstract and diagnostically important features. The dual capability of CNN-based fusion models ensures maintaining important diagnostic information such as tumor boundaries, tissue abnormalities, and vascular structures. Thereby keeping the fused image both precise and informative [22].
Beyond image quality, CNN-based fusion has significance to medical practitioners’ workflow. Using CNN, the fusion process is automated, which makes the interpretation and combination of multiple modalities less time-consuming compared with the manual process. The most significant benefit of this is in time savings, which are especially crucial during emergency cases, where diagnosis must happen as soon as possible. Furthermore, the decrease in manual intervention also decreases variability and subjectivity in diagnostics, resulting in more uniform and dependable diagnostic results across various healthcare environments [23].
2.3. Impact of CNN-Based Multi-Modal Medical Image Fusion on Healthcare
CNN-based multi-modal image fusion has a high impact on healthcare, especially in diagnosing rapidly and accurately and personalizing the treatment. CNN‐based fusion can create images that contain far greater anatomical and functional information than current techniques, allowing earlier and more accurate diagnoses with better patient outcomes. For example, in the field of cancer diagnosis, the combined fused images of PET and MRI can lead to early detection of tumors and, consequently, to achieving timely intervention. In addition, like neuroimaging, fusing MRI and fMRI gives a comprehensive view of the brain, helpful in precisely localizing functional defects or structural abnormalities, in conditions that require surgical management [24]. Another major impact of CNN-based fusion is on the contribution of precision medicine. In the process of personalized treatment planning, it is extremely important to consider the personal anatomical and physiological properties of the patient. The detailed and personalized view seen in the fused images allows clinicians to tailor treatments to the patient more specifically. In radiation therapy, for example, fused images are particularly useful because they allow precision striking of tumors with radiation while sparing surrounding healthy tissue. As a result, CNN-based fusion helps make treatments less risky and more effective, lowering the risk of complications and improving patients’ quality of life [25].
Furthermore, CNN-based fusion models have proved to be a must in developing the medical imaging field. The development and refinement of existing CNN-based fusion techniques help provide better imaging protocols, making it possible to study disease, track disease progression and gauge treatment response. On the other hand, this advancement results in the perpetual evolution of diagnosis tools, and CNN-based fusion methods shape the new standards in medical imaging. The implementation of these cutting-edge fusion techniques may also dictate future healthcare policy, including diagnostic procedure guidelines and treatment planning [26].
2.4. Challenges and Limitations in CNN-Based Multi-Modal Medical Image Fusion
2.4.1. Difficulty in Annotated Dataset Acquisition
- Large, annotated datasets are required to train CNN models effectively.
- Privacy issues, regulatory constraints, and a lack of multi-modal datasets hinder data acquisition.
- The expertise and time needed to annotate images make it challenging to create high-quality datasets [27].
2.4.2. Generalization Issues
- Without proper data, CNN models may fail to generalize, leading to inconsistent and inaccurate fusion results [27].
2.4.3. Computational Complexity
- High computational power and memory are required for training CNN models on large medical datasets.
- Resource demands (e.g., GPUs or cloud-based solutions) may not be accessible to all healthcare institutions.
- Real-time applications are limited due to the high computational demand, restricting integration into clinical workflows in resource-limited settings [28].
2.4.4. Lack of Interpretability
- CNN architectures are complex and often viewed as “black boxes.”
- Clinicians may struggle to understand the rationale behind fusion decisions.
- Transparency and trust in fused images are critical for accurate diagnosis, which is hindered by the lack of interpretability [29].
2.4.6. Skepticism from Healthcare Providers
- The lack of interpretability may lead to skepticism among healthcare providers, reducing motivation for adoption [29].
2.5. CNN-Based Multi-modal Medical Image Fusion: Step-By-Step Procedure
2.5.1. Step 1: Acquisition of Multi-Modal Medical Images
Once you have multiple medical images of the same subject captured from different imaging modalities like CT, MRI, PET, and Ultrasound, etc. Each modality provides distinct information.
2.5.2. Step 2: Preprocessing of Input Images
Next, the images are preprocessed to conform to the CNN model compatibility. It usually encompasses resizing of images, normalizing of pixel values and aligning the images by correcting some small spatial variations. To help the model better generalize the values, normalization (for instance, scaling the pixel values into a 0–1 range) is used, which puts all values of an additional modality within a standardized range.
2.5.3. Step 3: Feature Extraction Using CNN Layers
Each preprocessed input image is passed through some successive CNN layers, just like convolutional layers that apply a filter to find edges, textures or some pattern in the image. Use of pooling layers to decrease the number of spatial dimensions in feature maps, keeping essential information, and restricting the computational load. The CNN learns to keep both anatomical and functional features specific to each modality, which then helps it distinguish between anatomical and functional features.
2.5.4. Step 4: Fusion of Extracted Features
Following feature extraction, the features obtained from each modality are integrated by means of a fusion strategy. CNNs typically allow for three types of fusion.
2.5.4.1. Pixel-Level Fusion
Captures detailed spatial information at the channel using the raw pixel values, which might increase the noise.
2.5.5. Step 5: Reconstruction of Fused Image
To reconstruct the fused feature map back in the image format, a deconvolution or upsampling layer is utilized. The goal of the reconstruction stage is to synthesize a unified image that maintains crucial features from each modality as a high-quality image with additional diagnostic value.
2.5.6. Step 6: Post-processing
Finally, post-processing steps were applied to further refine the fused image (i.e., adjust contrast, use noise reduction filters, etc.) At this stage, sometimes the visibility of anatomical structures or functional details is enhanced, and the final output image is visually clear and diagnostically useful. The merits and demerits of CNN-based multi-modal medical image fusion are shown in Table 1.
2.6. Model Optimization, Adaptation, Future Research and Development
The model is fine-tuned to improve the CNN-based fusion process by optimizing parameters, trying various fusion strategies and employing advanced techniques such as transfer learning to make the model applicable for different datasets or imaging conditions. By optimization, the model is effective in various scenarios and can be generalized as applied to different patient cases and imaging equipment.
| Advantages | Disadvantages |
|---|---|
| Automatic Feature Learning | High Data Requirements |
| High Detail Preservation | Computational Complexity |
| Scalability | Lack of Interpretability |
| Flexibility in Fusion Levels | Generalization Challenges |
| Improved Diagnostic Accuracy | Risk of Over-Smoothing |
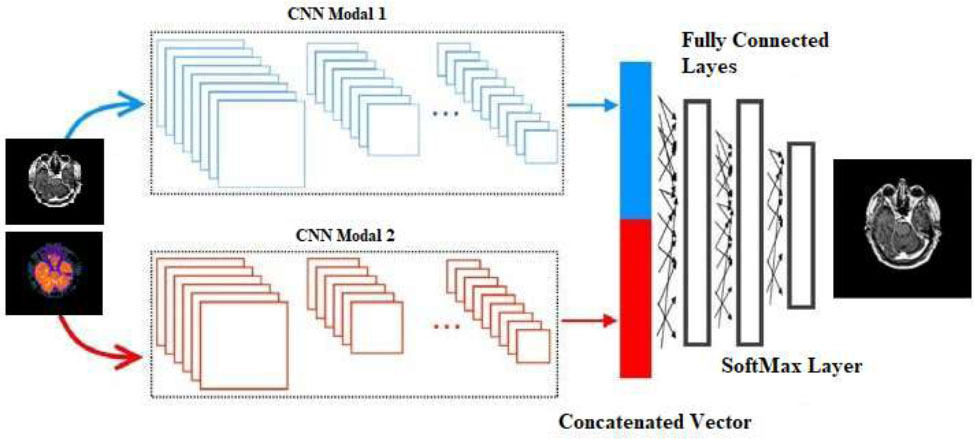
Future research may include further lightening of architectures to lessen computational demands, increasing the interpretation of models to increase acceptance from clinicians, and learning to adapt models to unseen imaging protocols. However, future advancements in this novel fusion model may lower the complexity of the CNNs to the point where they could be more feasibly incorporated into real-world healthcare settings, expanding the number of fused multimodal imaging scenarios that can be utilized for accurate and time-effective diagnosis and treatment. The general CNN-based multi-modal medical image fusion is shown in Fig. (2).
2.7. Algorithm: CNN-Based Multi-Modal Medical Image Fusion
The step-by-step process of fusing the source input images into a final fused image using a CNN. The CNN-based approach is explained in the sub-section.
2.7.1. Step 1. Input
CT_image ß Input medical image 1, for example, CT image
MRI_image ß Input medical image 2, for example, MRI image
2.7.2. Step 2. Preprocessing
CT_Image ß Normalize (Resize(CT_Image, Size), Range = [0, 1])
MRI_Image ß Normalize (Resize(MRI_Image, Size), Range = [0, 1])
2.7.3. Step 3. CNN Feature Extraction
Model ß Define_CNN(Input_Shape = (Height, Width, Channels))
CT_Features ß Model (CT_Image)
MRI_Features ß Model (MRI_Image)
2.7.4. Step 4. Fusion Rule Application
For each Pixel (i, j):
Weight_CT ß Compute_Weight(CT_Features(i, j))
Weight_MRI ß Compute_Weight(MRI_Features(i, j))
Fused_Feature (i, j) ß (Weight_CT * CT_Features(i, j)) + (Weight_MRI * MRI_Features (i, j))
3. RESULTS
Figs. (3a, b and 4a, b) illustrate the datasets of CT, MRI, and PET images [32, 33]. The dataset used in this paper for experimental purposes is publicly available, as it is an open-source database. Figs. (3c-j and 4c-j) show the visual quality outcomes of the comparison of CNN with other prevalent fusion methods on two different datasets. Zooming into the images reveals that the results are good. The edges and corners are effectively preserved. Uniformity is maintained, and no information is lost. The CNN is effective in fusing the CT and MRI images without loss of any information. Additionally, the results of CNN are also compared with various standard methods as shown in Figs. (3c-j and 4c-j). The CNN is compared with conventional methods like Principal Component Analysis (PCA), Discrete Wavelet Transform (DWT), Stationary Wavelet Transform (SWT), Wavelet Packet Decomposition (WPD), Multi-Singular Valued Dependency (MSVD), Non-Subsampled Contourlet Transform (NSCT), and Non-Subsampled Shearlet Transform (NSST), and the results are comparatively better than traditional methods in terms of visual and qualitative analysis. Upon thorough examination of the visual outcomes (Figs. 3c-j and 4c-j) and the parametric data (Tables 2 and 3), it can be concluded that the CNN demonstrates superior performance relative to the other standard methods evaluated. The NSCT and NSST method also shows better results that look competitive in comparison to CNN-based results. The comparative performance of CNN is better than all the conventional methods as shown in Figs. (3c-j, 4c-j) and Tables 2 and 3. It can be concluded that the CNN-based multi-modal medical image fusion shows comparatively better fusion results than traditional methods.
The CNN-based method excels in spatial detail retention, feature preservation, and overall visual quality. Although there is a slight trade-off in structural similarity, it still produces visually appealing images with high contrast and detail. The NSCT and NSST methods show balanced performance across metrics, providing good structural similarity and quality. These methods are ideal for tasks requiring both feature retention and coherence. The PCA makes it suitable for applications focusing on feature-rich fusion, though it sacrifices some spatial correlation. The WPD and DWT methods are weaker in retaining structural and feature-related information, leading to fused images that may appear less detailed or visually coherent. The SWT method indicates potential issues with contrast and information richness in the resulting images.
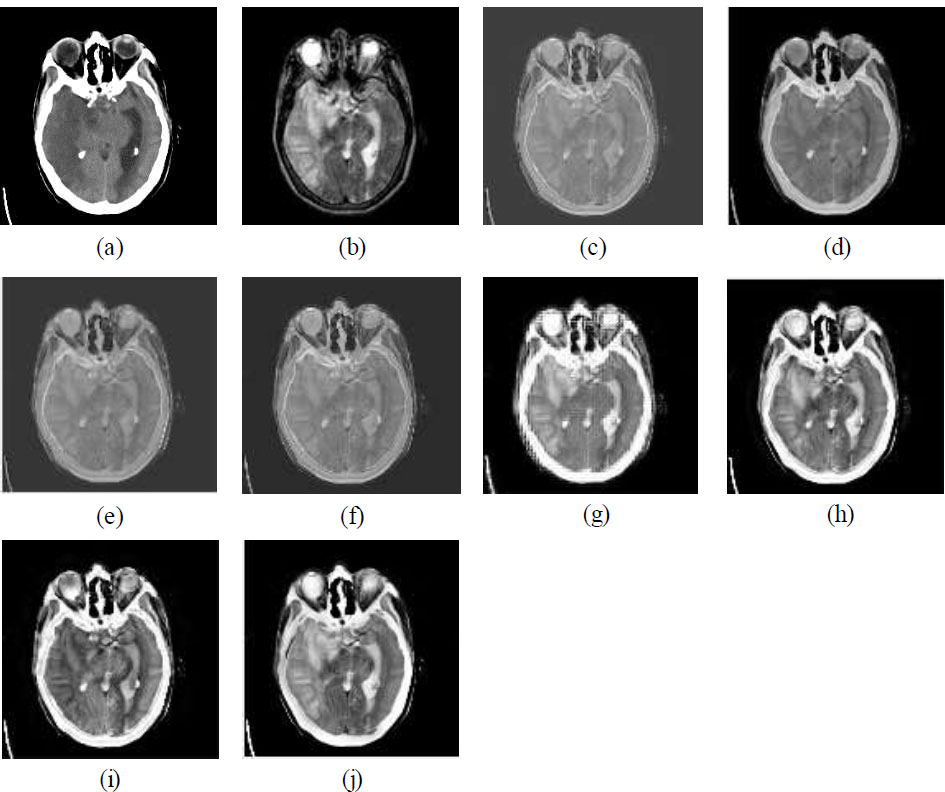
(a) CT image, (b) MRI image, (c) MSVD, (d) PCA, (e) DWT, (f) SWT, (g) WPD, (h) NSCT, (i) NSST, (j) CNN.
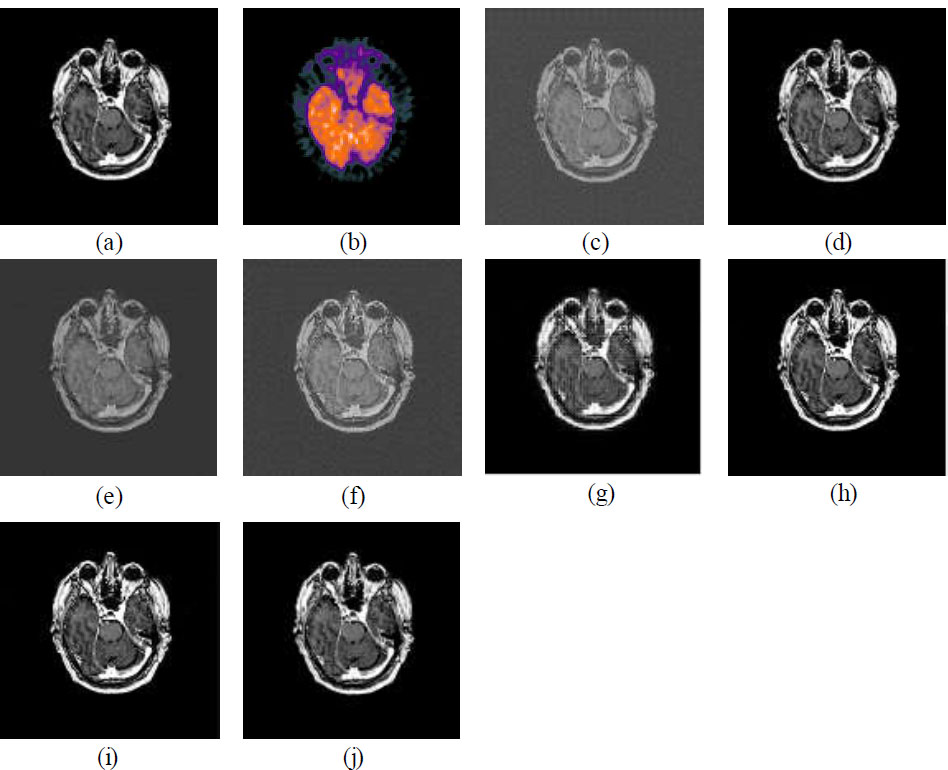
(a) MRI image, (b) PET image, (c) MSVD, (d) PCA, (e) DWT, (f) SWT, (g) WPD, (h) NSCT, (i) NSST, (j) CNN.
| Method | SCD | FS | FMI | FF |
|---|---|---|---|---|
| MSVD | 1.38 | 0.98 | 0.70 | 1.22 |
| WPD | 1.28 | 0.92 | 0.71 | 1.45 |
| PCA | 1.32 | 0.93 | 1.11 | 1.51 |
| DWT | 1.65 | 0.98 | 0.90 | 0.98 |
| SWT | 1.39 | 0.98 | 0.91 | 1.35 |
| NSCT | 1.45 | 0.99 | 0.98 | 1.71 |
| NSST | 1.43 | 0.91 | 0.95 | 1.74 |
| CNN | 1.70 | 0.86 | 1.21 | 1.79 |
The CNN-based method excels in all metrics, producing visually rich, high-contrast, and well-balanced fused images. It is the best choice when visually superior fused images are required, such as medical imaging or surveillance. The NSCT and NSST methods provide balanced performance across all metrics, making them suitable for applications requiring good visual quality with slightly lower computational demands compared to CNN. The WPD method performs moderately well in entropy and fusion index, making it a viable choice for scenarios where high entropy is prioritized over contrast. The PCA method shows reasonable performance but falls short in contrast and detail retention. The MSVD and DWT method shows poor performance, leading to visually dull images with low contrast, brightness, and information content.
| Method | SD | M | E | FI |
|---|---|---|---|---|
| MSVD | 40.11 | 19.52 | 0.90 | 20.17 |
| WPD | 60.70 | 30.65 | 3.34 | 31.56 |
| PCA | 56.55 | 26.57 | 0.98 | 28.03 |
| DWT | 38.60 | 27.50 | 1.31 | 22.47 |
| SWT | 40.90 | 19.52 | 1.38 | 20.60 |
| NSCT | 63.32 | 29.11 | 3.01 | 31.81 |
| NSST | 63.76 | 29.13 | 2.77 | 31.88 |
| CNN | 64.91 | 31.89 | 3.51 | 32.31 |
4. DISCUSSION
There is no reference image for the comparison. Therefore, objective method performance assessment metrics without a reference image are used for the overall comparison of M3IF-NSST-MI with other methods. The metrics used are Functional Mutual Information (FMI), Fusion Symmetry (FS), Mean (M), Fusion Factor (FF), Standard Deviation (SD), Entropy (E), Fused Index (FI), and Sum of Correlation Difference (SCD). Except for FS, all the metrics should have higher values for better results. Only FS should have a lower value for better results. Table 2 shows the quantitative analysis of different methods (MSVD, WPD, PCA, DWT, SWT, NSCT, NSST, and CNN) based on four metrics, SCD, FS, FMI, and FF. The key observations include the high scores of SCD and CNN. Whereas, NSCT scores the highest in terms of FS score, suggesting better feature similarity, while CNN has the lowest. CNN outperforms other methods with the highest FMI value, reflecting improved fusion metric performance. CNN also achieves the highest FF score, showcasing its strong fusion capabilities. Based on this data, CNN-based fusion methods shine in overall performance metrics, particularly SCD, FMI, and FF.
Table 3 evaluates different methods (MSVD, WPD, PCA, DWT, SWT, NSCT, NSST, and CNN) based on four metrics, SD, M, E, and FI. The key insights from these evaluations demonstrate that CNN achieves the highest SD score, which indicates the best variability in the fused image. CNN outperforms other methods with the highest mean value, suggesting better brightness retention in the fused image. CNN also achieves the highest E value, reflecting the most information-rich fused image. CNN secures the highest FI score, demonstrating the most efficient and balanced fusion performance. CNN leads in all metrics (SD, M, E, and FI), indicating superior performance in fusion compared to other methods.
The graphical representation of the data presented in Tables 2 and 3 is illustrated in Figs. (5 and 6), respectively, using a spider chart. The findings presented in Tables 2 and 3, as well as in Figs. (5 and 6), represent average outcomes derived from experiments conducted on over 100 datasets. In Fig. (5), the CNN method covers the largest area on the chart, highlighting its superior performance in SCD (1.7), FMI (1.21), and FF (1.79). It shows a trade-off in FS (0.86), which is lower compared to other methods, but is compensated by its high scores in other metrics. The NSCT and NSST methods show balanced performance with slightly lower scores than CNN in FF and SCD, but higher scores in FS (0.99 for NSCT and 0.91 for NSST). The PCA method performs moderately well in FMI (1.11) and FF (1.51) but lags in SCD and FS. The WPD and SWT methods have a smaller area compared to CNN, indicating weaker overall performance. For example, WPD has a low FMI (0.71), while SWT struggles in FF (1.35). The MSVD and DWT methods show subpar performance in metrics like FMI and FF, with a relatively smaller contribution to the overall chart area.
In Fig. (6), the CNN method covers the largest area in the chart, clearly outperforming all other methods. It has the highest SD score, indicating superior contrast and detail retention.
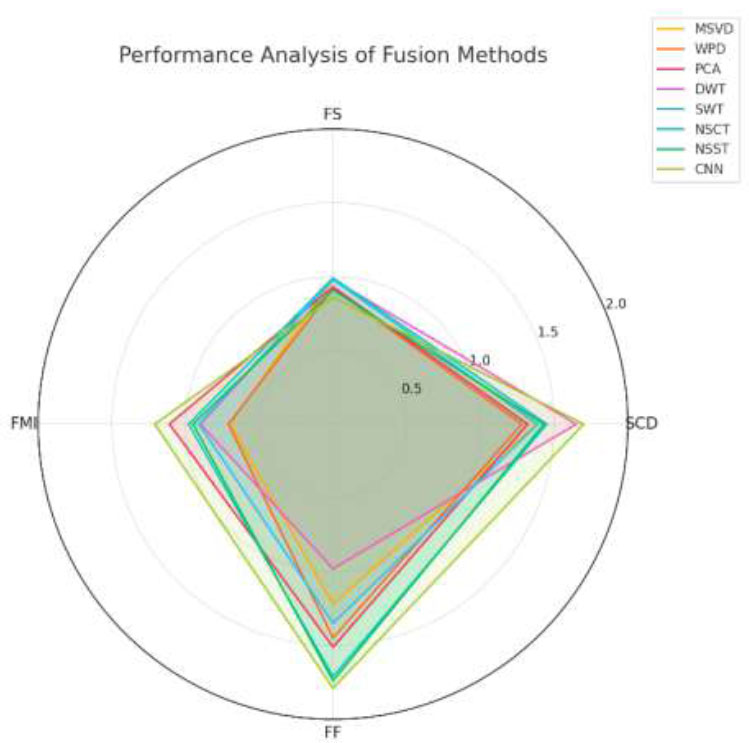
Spider chart analysis of various metrics (SCD, FS, FMI, and FF).
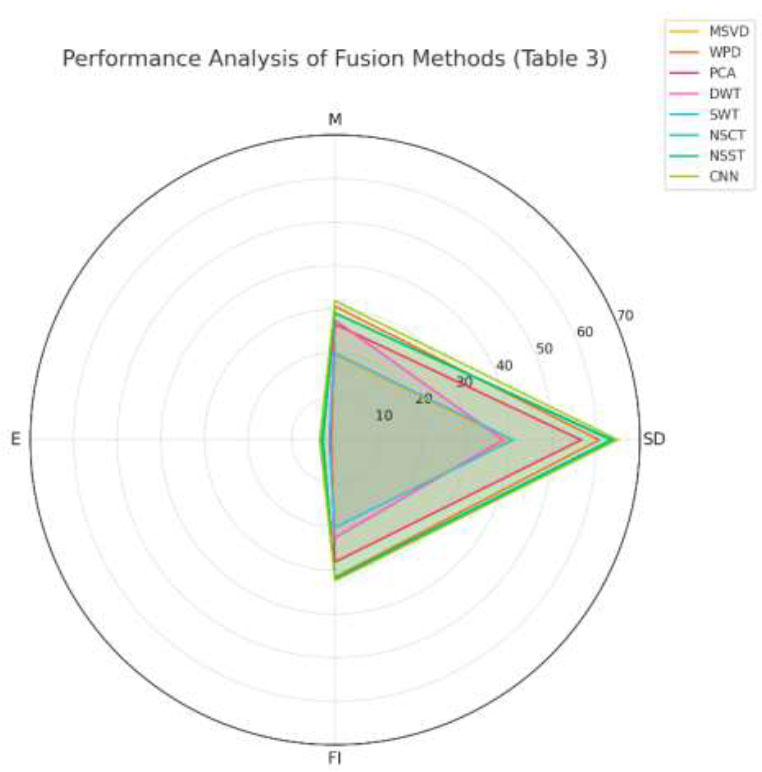
Spider chart analysis of various metrics (SD, M, E and FI).
As well as the highest M score, reflecting better brightness preservation. Additionally, it obtains the highest E score, showcasing superior information retention, and overall has the best FI value, solidifying its dominance. The NSCT and NSST methods perform well and are closely aligned with CNN in most metrics, with their SD scores of 63.32 and 63.76, respectively, nearly as high as CNN. Their FI values are 31.81 and 31.88, respectively, competitive with CNN, demonstrating effective overall fusion performance. Whereas, their E scores are slightly lower than CNN but still above most other methods. The PCA method performs moderately, with good scores in M (26.57) and FI (28.03), but lags in E (0.98) and SD (56.55). The WPD method is the second-best in FI (31.56) and performs decently in M (30.65) but falls behind in SD (60.7) and E (3.34). The MSVD and DWT methods underperform across all metrics, with particularly low FI and E, indicating limited utility for high-quality fusion tasks.
Since the fusion results difference are not visible in the Figs. (3 and 4) with the naked eye. Fig. (7) is introduced in this paper, which shows a zoomed-in view of Fig. (3), highlighting the superior performance of CNN-based fusion methods.
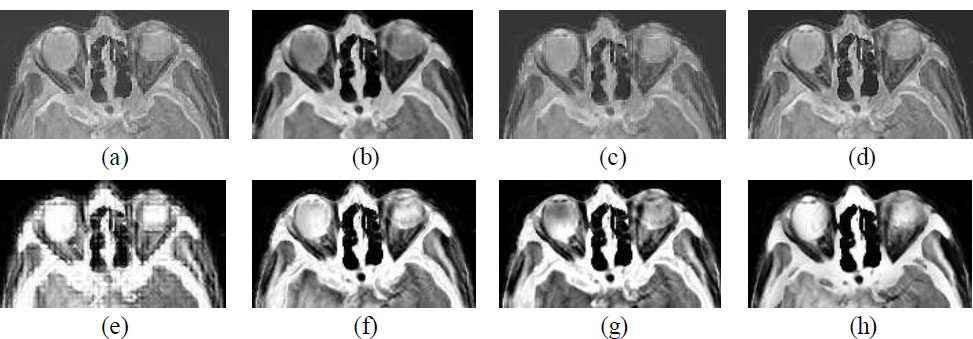
Zooming fusion results (a) MSVD, (b) PCA, (c) DWT, (d) SWT, (e) WPD, (f) NSCT, (g) NSST, (h) CNN.
The image is visibly smooth and maintained in CNN-based fusion results in comparison to other methods. Although NSCT and NSST-based fusion results also show decent results in terms of tissue and other fine details preservation but overall clarity can be seen in the CNN-based method.
CONCLUSION
This paper examines the significance of CNN-based multimodal medical image fusion, combining data from modalities like CT, PET, and MRI into a single, informative image for enhanced diagnosis and treatment planning. CNN-based fusion integrates complementary anatomical and functional details, enabling automated feature extraction, reduced manual input, and greater diagnostic precision. Key benefits include lower healthcare costs and improved efficiency, particularly valuable in oncology, neurology, and cardiovascular imaging. Challenges include high computational demands, data requirements, and limited interpretability. Solutions such as lightweight architectures, transfer learning, and explainable AI are discussed, highlighting CNN-based fusion’s potential to improve patient outcomes and advance medical imaging. In the coming years, advancements in CNN-based multimodal image fusion are poised to transform medical imaging by integrating deep learning innovations with efficient network architectures and enhanced interpretability. Reducing the computational demands of CNN models holds promise for making CNN-based fusion feasible in clinical settings. Data scarcity, a significant challenge, can be addressed through transfer learning and domain adaptation, enabling models trained on specific datasets to generalize effectively across different imaging conditions. Furthermore, incorporating Explainable AI (XAI) into CNN-based fusion frameworks could significantly improve model interpretability, helping clinicians understand both the fusion processes and the resulting outputs. In diagnostic applications, where accuracy is paramount, transparency becomes especially critical. CNN-driven multimodal image fusion offers tremendous potential for enhancing healthcare by combining diverse imaging modalities to improve diagnosis, treatment planning, and patient outcomes. Although challenges remain, current research and technological advancements are expected to mitigate these limitations, pushing the boundaries of medical imaging through CNN-based fusion.
LIST OF ABBREVIATIONS
| CT | = Computed Tomography |
| PET | = Positron Emission Tomography |
| MRI | = Magnetic Resonance Imaging |
| CNN | = Convolutional Neural Network |
AVAILABILITY OF DATA AND MATERIALS
The data and supportive information are available within the article.
CONFLICT OF INTEREST
Dr. Vinayakumar Ravi is the Associate Editorial Board Member of the journal The Open Bioinformatics Journal.
ACKNOWLEDGEMENTS
Declared none.

