
Machine Learning Algorithms in Cardiology Domain: A Systematic Review
Abstract
Background:
It could be seen in the previous decades that Machine Learning (ML) has a huge variety of possible implementations in medicine and can be of great use. Nevertheless, cardiovascular diseases cause about a third of the total global deaths.
Does ML work in the cardiology domain and what is the current progress in this regard? To answer this question, we present a systematic review aiming at 1) identifying studies where machine learning algorithms were applied in the domain of cardiology; 2) providing an overview based on the existing literature about the state-of-the-art ML algorithms applied in cardiology.
Methods:
For organizing this review, we adopted the PRISMA statement. We used PubMed as the search engine and identified the search keywords as “Machine Learning”, “Data Mining”, “Cardiology”, and “Cardiovascular” in combinations. Scientific articles and conference papers published between 2013-2017 reporting about implementations of ML algorithms in the domain of cardiology have been included in this review.
Results:
In total, 27 relevant papers were included. We examined four aspects: the aims of ML systems, the methods, datasets, and evaluation metrics. The major part of the paper was aimed at predicting the risk of mortality. A promising branch of Machine Learning, the ‘Reinforcement Learning’, was also never proposed in the observed papers. Tree-based ensembles are common and show good results, whereas deep neural networks are poorly represented. Most papers (20 of 27) have used datasets that are hardly available for other researchers, e.g. unpublished local registries. We also identified 28 different metrics for model evaluation. This variety of metrics makes it difficult to compare the results of different researches.
Conclusion:
We suppose that this systematic review will be helpful for researchers developing medical machine learning systems and for cardiology in particular.
1. INTRODUCTION
1.1. Background
Cardiovascular diseases (CVD) are a group of disorders of the heart and blood vessels. Data from the World Health Organization shows that CVDs are a leading cause of deaths worldwide for both sexes and all ages. In particular, CVDs caused 17.3 million deaths in 2013. This is 45% of all non-communicable disease deaths and 31.5% of all global deaths. More deaths worldwide were caused by CVDs than all communicable, maternal, neonatal, and nutritional disorders combined, which is twice more than those caused by cancer [1].
These facts illustrate the importance of dealing with CVDs. Artificial intelligence and clinical decision support can help doctors provide better and more personalized treatment to their patients. A lot of efforts have been applied during the previous years to implement clinical decision support systems. A big class of clinical decision support systems is based on machine learning. It has been shown in the previous decades that machine learning, as well as other branches of artificial intelligence (AI), has a broad variety of possible implementations in medicine and can be very helpful. The first and currently used definition of ML was proposed by A. Samuel [2]: “ML is a field of study that gives computers the ability to learn without being explicitly programmed”. An ML program can learn from medical data that has been collected by physicians and devices for years to make predictions, prognosis, or diagnosis.
There are many particular applications of AI and ML algorithms as tools to support decision making for different medical tasks. For instance, artificial intelligence classifiers have been used in urology diagnosis [3], in oncology and breast cancer diagnosis [4-6], in the diagnosis of hypoglycemic episodes [7], in skin cancer classification and diagnosis [8, 9], as well as for medical image analysis [10].
In our research, we aimed to identify and analyze the current applications of ML algorithms that are employed in the cardiology domain and presented in recent scientific papers.
1.2. Related Works
There are previous works devoted to the analysis of different aspects of artificial intelligence systems in medicine. We discuss some of them below:
Considered the main characteristics of predictive clinical data mining and focused on two specific aspects: the methods able to deal with temporal data and the efforts performed to build data mining models based on the results of molecular medicine.
A systematic review by Palaniappan et al. [11] examined the processing of sensor data, signal processing, classification, and statistical methods to analyze lung sounds reported in previous research.
Review of the Literature by Triantafyllidis et al. [12] observed applications of machine learning in real-life digital health interventions, aiming to improve the understanding of researchers, clinicians, engineers, and policymakers in developing robust and impactful data-driven interventions in the health care domain. The finding of the review is the fact that health interventions engaging machine learning algorithms in real-life studies can be useful and effective. The authors also reported about the necessity to conduct further studies in intervention settings following evaluation principles and demonstrating the potential of machine learning in clinical practice.
The survey by Wallert et al. [13] described biomedical information systems for decision support, their application protocols and methodologies, and also suggested the future challenges and directions.
Melillo et al., in their review [14-20], underlined that clusters of computer technologies are used for pain management by processing clinical data for the development of clinical decision support systems (CDSS). The clusters are rule-based algorithms, artificial neural networks, nonstandard set theory, and statistical learning algorithms. The authors detected methodologies for content processing such as terminologies, questionnaires, and scores.
Machine learning in lung sound analysis was examined by Kalidas et al. [19]. The authors highlighted specific lung sounds/disorders, the number of subjects, the signal processing and classification methods, and the outcome of lung sounds analysis using machine learning methods based on previous research. This review also contains recommendations for further improvements.
The survey by Eerikainen et al. [20] presents existing clinical decision support systems, recapitulates actual data on the application and impact of clinical decision support systems in practice, and recommendations for using these systems outside the research.
Applying natural language processing (NLP) techniques in healthcare was considered in the paper by Rajagopalan et al. [21]. This review provides the concept of NLP, the applications of NLP, and the challenges of NLP systems in healthcare.
The review “Using data mining techniques in heart disease diagnosis and treatment” [22] indicates shortcomings in the research on heart disease diagnosis and suggests a model to systematically resolve those shortcomings.
Despite the great interest in the topic, a number of issues have not been considered in detail. The existing reviews do not reflect the aspects people developing their AI systems might be interested in. For instance, what ML methods were applied and how efficient they were; in what way the efficiency of the algorithms and systems is usually measured and which metrics are used if so; what kind of data is used for such systems and what can be a source of the data. An overview of these questions can be relevant for researchers and developers who are going to develop an ML system for a particular medical field. We have discussed some of these issues as the objectives of our study.
There has been an increasing interest in the application of artificial intelligence since 2014 in the industry [17]. In this regard, we have considered the papers published since 2013, for a systematic review.
1.3. Objectives
This review aims at 1) identifying studies where machine learning algorithms were applied in the cardiology domain; 2) providing an overview based on the identified literature of the state-of-the-art ML algorithms applied in cardiology.
None of these aims have been reported in detail in previous works. It makes this systematic review a significant contribution to developing the field by helping and guiding researchers on what can be useful in their work and what can be a further way in their research and development.
2. RESEARCH METHODS
For organizing this review, we have employed the PRISMA statement. PRISMA is a set of items for reporting systematic reviews and meta-analyses that are focused on reporting reviews and evaluating randomized trials but can also be used as a basis for reporting systematic reviews [14, 15]. For the review, we have adopted the PRISMA statement and have identified the following items: review questions, information sources, search strategy, and selection criteria.
2.1. Review Questions
We analyzed the studies in terms of the following four questions.
Aims of the system. What is the system focused on and what is the output of the system?
We identify papers that report on the systems engaging ML methods in the domain of cardiology. We want to find out what tasks are the systems aimed at and what kind of output they produce.
Methods and algorithms. What algorithms were applied in the system?
There are plenty of ML algorithms that can be used to predict, classify, or estimate medical data. Different algorithms could be more suitable and efficient or less dependent on specific data or a particular task. We aimed at identifying what algorithms were implemented in research projects that applied ML techniques in cardiology.
Data sources. What dataset is used? How big is it? How many features/parameters does it have?
Any machine learning system needs a relevant dataset to be trained and validated. One of the biggest issues in developing a machine learning system is to get data for training and evaluation. We explored the datasets that were used in the observed researches, how many features and samples they had, and whether other researchers could access the dataset.
Algorithm evaluation. What metrics were used to evaluate the system?
Every system needs to be evaluated and there are many different metrics to evaluate them. We examined observed papers to identify and analyze the metrics that were engaged to evaluate the system.
2.2. Bibliographic Search Process
We identified the search keywords machine learning, data mining, cardiology,and cardiovascular. The keywords were combined in the search statement as machine learning OR data mining AND cardiology OR cardiovascular. PubMed has been employed as the search engine.
2.3. Selection Criteria
Table 1 provides the inclusion and exclusion criteria that were applied to select papers. We included scientific articles and conference papers in English published between 2013 and 2017 devoted to the application of ML methods in the field of cardiology. In addition to the criteria listed in Table 1, we did not consider the papers where we could not clearly identify information regarding our review questions.
3. RESULTS
Bibliographic search identified 372 papers (Fig. 1). Screening by titles revealed that 218 works were not related to the topic. Further screening by abstracts excluded 33 works not related to the topic and 54 papers that did not cover the implementation of any ML method. Full-text examination of 67 works led to excluding 8 more works as those were not related to the topic, 11 for not containing any ML method implementation, and 21 for not being scientific articles (review, dissertation/thesis, book chapter, comparative study, etc). Finally, 27 scientific articles or conference papers written in English and reporting about the implementation of an ML method or algorithm in cardiology were included in this review.
| Facets | Inclusion Criteria | Exclusion Criteria |
|---|---|---|
| Published | between 2013-2017 | until 2013 |
| Study Type | scientific article or proceedings paper | not a scientific article (review, dissertation/thesis, book chapter, comparative study, etc.) |
| Research content | devoted to the application of ML methods in cardiology | not related to the topic; does not contain a description of any certain ML method |
| Language | English | Not in English |
3.1. Aims of the Systems and the Outcomes
Based on the declared aims of the papers, we divided the papers into four groups and several papers were left out of that classification (Table 2). The major part of the articles (12 of 27) was aimed at risk prediction or mortality prediction. For instance, Lezcano–Valverde et al. [16] reported about the development of a mortality prediction model for rheumatoid arthritis patients based on demographic and clinical-related variables collected during the first two years after disease diagnosis; Verma et al. [13] presented a model to identify and confirm coronary artery disease cases by using clinical data that can be easily collected at hospitals.
Eight works, as an objective, considered a system for the diagnosis of cardiovascular disease development. For example, Wallert et al. [18] reported construction algorithms predicting two-year survival. Another example from this category is the study of Melillo et al. [19] where the aim was to develop predictive models for risk classification for hypertensive patients.
The next category contains two works [20, 21] aimed at classifying a cardiac alarm as true or false and reducing false alarms in intensive care units. The last group is represented by two papers [22, 23] related to the classification of ECG signals or heart sounds.
Three works were left out of the classification. Xiong et al. [24] proposed a system for determining the physiological manifestation of coronary stenosis from CTA images. Sengupta et al. [25] provided a pilot study to aid standardized assessments and support the quality of interpretations of cardiac imaging. The study of Seyednasrollah et al. [26] used childhood clinical factors and genetic risk factors for predicting adulthood obesity. This relates to cardiology because the authors emphasize that obesity is one of the risk factors for cardiovascular disease and early prediction of obesity is essential for CVD prevention.
All papers in our study are related to solving the problems of classification, which is a type of task, where a computer program is asked to specify, which k category a certain input belongs to. To solve this task, the learning algorithm usually produces a function f. When y=f(x), the model assigns an input described by vector x to a category identified by numerical code y [44]. Such systems take an input of a set of samples, each sample belonging to a class. The output for a new sample is a class that the sample has the highest probability of belonging to.
We grouped the papers according to the number of classes that they deal with. Most of the works (21 of 27) classify data into two classes, the others deal with 3, 5, or 6 (Table 3). Below, we provide some examples for every classification group.
Arabasadi et al. [36] reported about a system that predicts whether the patient has CAD or not. Wallert et al. presented [18] an algorithm that differentiates survivors and non-survivors in the two years after their first myocardial infarction. Ruiz-Fernández et al. [27] implemented a system for classifying a risk related to congenital heart disease surgery among three types: low complexity, medium complexity, and high complexity. Li et al. [43] provided a five-level ECG signal quality classification algorithm instead of the commonly used two-level (clean or noisy) classification. In the paper by Ambale-Venkatesh et al. [35], the system predicts six cardiovascular outcomes in comparison with standard cardiovascular risk scores. Table 4 shows the aim of the system and the number of classes used for classification.
3.2. ML Methods and Algorithms
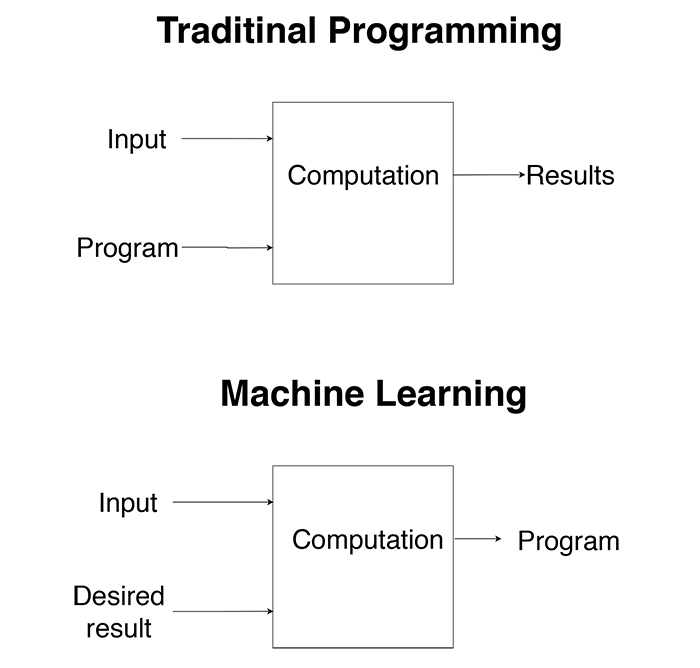
The basic concept of ML is that machines use data to create a program or to learn a target function F that best maps input variable X to output variable Y. In contrast to traditional programming, in ML we do not give the computer a function or a program to get output according to it. Instead, we give the computer examples of inputs and desired outputs to create a program to get the right output for unobserved inputs (Fig. 2).
There are three groups of Machine Learning algorithms: supervised learning, unsupervised learning, and reinforcement learning. In our work, we observed methods that had been applied in the selected papers. In some papers, ML methods were applied not only for the main task of the work such as diagnosis or predictions but also for selecting attributes or data preprocessing. The work is focused on the ML methods that were used in order to reach the main research task. In other words, here we report about classification algorithms and methods or the prediction model itself.
| Aim/N of classes | 2 classes | 3 classes | 5 classes | 6 classes |
|---|---|---|---|---|
| Diagnosis of CAD | [13, 36, 38, 39, 41, 42] | [37, 40] | - | - |
| Risk or mortality prediction | [18, 19, 28-34] | [27] | [16] | [35] |
| Classification of cardiac alarm as true or false | [20, 21] | - | - | - |
| ECG signal and heart sound classification | [23] | - | [43] | - |
| Other | [24-26] | - | - | - |
Fifteen out of 27 works adopted more than one method. For example [29], adopted six supervised classification ML algorithms and compared their predictive performance. We consider all the indicated methods. Table 5 provides a group of methods and works that applied these methods. Supplement 2 also provides methods and papers but in a paper-oriented way.
| Algorithm | Papers | N of papers | ||
|---|---|---|---|---|
|
Trees and Boosting |
RF Random Forest | [16, 18, 19, 21, 23, 24, 29, 30, 34, 35, 38, 42] | 12 | 28 |
| DT Decision trees | [13-19, 27, 28, 37, 38, 40] | 8 | ||
| Gradient boosting DT | [26, 30, 34] | 3 | ||
| AdaBoost | [19, 24, 29, 38] | 4 | ||
| LogitBoost | [32] | 1 | ||
| ANN | MLP Multi-layer perceptron | [13, 19, 27, 30, 33, 36, 37] | 7 | 12 |
| Other | [27, 38, 41, 42] | 5 | ||
| LogitBoost | [32] | 1 | ||
| LR Logistic Regression | [13, 18, 29-31, 34, 39] | 7 | 7 | |
| SVM Support Vector Machines | [18-20, 37, 41-43] | 7 | 7 | |
| Others | [17, 27, 35, 37, 38, 41] | 6 | 6 | |
| Naïve Bayes (NB) | [19, 24, 29, 38, 39] | 5 | 5 | |
| k-NN k-Nearest Neighbors | [38, 41] | 2 | 2 | |
3.3. Decision Trees
Tree structures are used for classification. Nodes represent features from instances, and branches represent values. Leaf nodes represent decisions or classes. Based on the feature values of instances, the decision trees classify the instances [45].
There is a decision tree generating algorithms such as ID3 [46], its extension C4.5 [47], and C5/See5. Some improvements done in C4.5 are handling training data with missing attribute values, attributes with differing costs, and continuous attributes. C5 is an improvement of C4.5. C5 is more efficient in terms of speed, memory usage, size of a decision tree, and it includes boosting [48].
3.4. Boosting and Ensembles
The main idea of ensemble methods is to combine “weak” classifiers (e.g. SVM or decision trees) to create a final “strong” one [49]. Predictions from a single classifier can be weighted to get the final prediction (boosting), or the final prediction can be obtained as the average or major value (bagging). The difference between ensemble algorithms is the way of getting the final prediction and classifiers.
Ensembles of decision trees are very common and known. These include rotation forests with alternating decision tree as an underlying classifier [28, 29], RF, and GBDT (Table 5). AdaBoost (Adaptive Boosting) is a popular boosting classification algorithm and it was the first algorithm that could adapt to weak learners. It was applied in Shouval’s work [29] to predict mortality after myocardial infarction and was reported in Melillo’s paper [19] to predict cardiovascular events. Both papers applied six different ML methods (including AdaBoost) and compared the results. Both LogitBoost and AdaBoost are based on an additive logistic regression. However, AdaBoost minimizes the exponential loss and LogitBoost minimizes the logistic loss. Motwani et al. [32] implemented LogitBoost to predict mortality in patients with coronary artery disease.
In contrast to the previous works, the two following works did not use DT as underlying models. Narula et al. [42] presented an ensemble model with three different algorithms (support vector machines, random forests, and artificial neural networks) and the final prediction was obtained by majority voting. Lo et al. [38] also reported about an ensemble voting mechanism where multiple classifiers were combined to obtain better prediction performance.
3.5. Random Forest or Random Decision Forests
A random forest classifier is an ensemble learning method for classification and regression that combines a collection of decision trees [50, 51]. To build a random forest classifier, a training dataset is divided into subsets. Every subset builds an independent decision tree. For every tree, different training examples are used. In other words, subsets must not overlap. To classify a new object, results from all trees are compared and the class that appears more often is considered as an answer. The important advantage of this method is that more trees will not overfit a model.
3.6. Artificial Neural Network and MLP
Artificial neural networks are the models taking their inspiration from the human brain. The core element of the model is a neuron that has connectors called synapses. Neurons are connected to each other and the model can be represented with Graph theory. A multilayer perceptron (MLP) is a simple architecture that is able to classify objects. MLP has three types of neurons that form layers: input, output, and hidden. All neurons from one layer connect with all the neurons of the next layer. Every connection has a weight that is to be adjusted during the training process. Beside MLP, plenty of other neural network architectures were applied in medical image processing, data extracting from medical records, and other areas.
3.7. Logistic Regression (LR)
Logistic Regression is a classification algorithm uses a logistic function. The output of logistic regression is a probability that the given input belongs to a certain class [52-54].
3.8. Support Vector Machine (SVM)
SVM is one of the most robust and accurate methods among all ML algorithms [45]. It requires a small sample set and generates patterns from that. It is insensitive to the number of dimensions. In the case of a linearly separable dataset, a classification function is a separating hyperplane f(x) that passes through the middle of the two classes to separate them [45]. When the function is determined, data instance xn can be classified by simple testing. If f(xn) > 0, then xn belongs to the positive class.
3.9. Naive Bayes Classifier
Naive Bayes is a set of algorithms based on Bayes’ theorem of the assumption of the probability of independence among predictors. One of the main advantages of these algorithms is that it is easy and fast to apply for both binary and multi-class classifications. The algorithm works especially well if predictors are actually independent, but it is almost impossible for real-life data [55-57].
3.10. K-NN
The k-nearest neighbors algorithm searches for the k-nearest training instances and classifies the new instance into the most frequent class of these k instances.
3.11. Datasets and Data Sources
Every system needs a dataset for training and validation. We divided all datasets used in the observed studies into two groups: publicly available datasets and datasets that could not be easily accessed. Examples of the latter are datasets that are collected in medical institutions or obtained from a register. The first group comprises seven studies and eight databases (Table 6), but some datasets are used in more than one study and some researches use more than one dataset. Li et al. [43] used the PhysioNet/CinC Challenge 2011 database to develop a classifier and engaged real ECGs from the MIT-BIH arrhythmia database (MITDB) to evaluate the classification performance. Lo et al. [38] obtained an integrated dataset collected from 4 datasets provided by the UC Irvine Machine Learning Repository. They included the Hungarian dataset, the Switzerland dataset, the Cleveland dataset, and the Long Beach VA dataset. The new dataset contains 822 cases diagnosed either with or without CAD. The dataset is also available from the UC Irvine Machine Learning Repository as Heart Disease Data Set [58].
The second group includes 17 papers and datasets (Table 7). For the works not indicated in Tables 6 and 7, the sources of the data could not be clearly identified.
| Title | # of samples | # of attributes | Paper |
|---|---|---|---|
| PhysioNet/CinC Challenge 2011 database | 2658 | ECG | [43] |
| MIT-BIH arrhythmia database (MITDB) | 47 | ECG | [43] |
| Z-Alizadeh Sani dataset | 303 | 54 | [36] |
| Cleveland Heart Disease data set | 303 | 76 | [38] |
| MESA study (Multi-Ethnic Study of Atherosclerosis) | 6 814 | 735 | [59] |
| PhysioNet/CinC Challenge 2015 dataset. | 1 250 | ECG | [21, 60] |
| Physionet/CinC Challenge 2016 dataset | 3126 | heart sound | [23] |
| Heart Disease Data Set | 822 | 76 | [38] |
3.12. UC Irvine Machine Learning Repository
The UCI Machine Learning Repository collects datasets that can be used for empirical analysis of machine learning algorithms. The website of the repository says: “it has been cited over 1000 times, making it one of the top 100 most cited “papers” in all of computer science” [58]. The repository contains a total of 399 datasets classified by domains, task type, data type, etc. The Life Science category includes 91 datasets related to biology and medicine. In our research, three papers [13, 36, 38] used three datasets from this repository: Z-Alizadeh Sani dataset, the Cleveland Heart Disease dataset, and the Heart Disease Data Set. We will consider them below.
3.13. Z-Alizadeh Sani Dataset
Z-Alizadeh Sani dataset contains records of 303 patients, each of them having 54 features. The features are arranged into four groups: demographic, symptom and examination, ECG, and laboratory and echo features [61]. Each patient can belong to one of the two possible categories: CAD or Normal. Patients are categorized as CAD if their coronary artery diameter narrowing is greater or equal to 50%, otherwise, a patient is categorized as Normal [61, 62]. The dataset was employed in a study [36] and provided by the UCI Machine Learning Repository; an updated version of this dataset is available there as well.
3.14. Cleveland Heart Disease Dataset
The dataset was published in 1988 and contains 76 attributes and 303 instances. The proposed task for the dataset is to predict the presence of heart disease for the patient. The target field is an integer-valued from 0 to 4 [58]. Fifty-four percent of samples represent patients without heart disease and 46% with heart disease. The dataset webpage also says that researchers usually use a subset of 14 of the 76 presented attributes. The subset includes age, sex, chest pain type, resting blood pressure, serum cholesterol in mg/dl, fasting blood sugar, resting electrocardiographic results, maximum heart rate achieved, exercise-induced angina, ST depression, slope of the peak exercise ST segment, number of major vessels and diagnosis of heart disease (the predictable attribute). The dataset is provided by the UCI Machine Learning Repository. The dataset was used as the main data source in one study [38] and adopted as a benchmark dataset in another [13].
| Name | # of samples | # of attributes | Paper |
|---|---|---|---|
| Cardiovascular Foundation of Colombia | 2 432 | 87 | [27] |
| Japanese health check-up data | 61 313 | 11 | [34] |
| Northwestern Medical Faculty Foundation (NMFF) | 7 463 | 980 | [28] |
| Department of Cardiology, Indira Gandhi Medical College, Shimla, India | 335 | 26 | [13] |
| Acute Coronary Syndrome Israeli Survey (ACSIS) registry [71] | 13 422 included 2 782 |
54 | [29] |
| Clinical Practice Research Datalink | 383 592, included 378 256 |
30 | [30] |
| Bio-signal Research Center of the Korea Research Institute of Standards and Science | 214 | 20 | [37] |
|
SWEDEHEART, the national quality Register
for Information and Knowledge about Swedish Heart Intensive Care Admissions (RIKS-HIA) |
51 943 | >100 | [18] |
| Cardiology service of Hospital Clínic in Barcelona (Spain) | 1 390 | 2100 | [41] |
| The clinical trial of patients after non-ST-elevation acute coronary syndrome (NSTEACS) | [31] | ||
| Korean Health and Genome Epidemiology study database (KHGES) | 12 789 | 41 | [39] |
| COronary CT Angiography EvaluatioN For Clinical Outcomes: An InteRnational Multicenter (CONFIRM) registry | 10 030 | 69 | [32] |
| Cardiovascular Risk in YFS (Young Finns Study) | 2 262 | 97 | [26] |
| Centre of Hypertension of the University Hospital Federico II | 139 | 33 | [19] |
| Autonomic nervous system (ANS) unit of the cardiology department of Avicenne hospital | 263 | 11 | [40] |
| Hospital Clínico San Carlos RA cohort (HCSC-RAC) and Hospital Universitario de La Princesa Early Arthritis Register Longitudinal (PEARL) | 1 741 | 12 | [16] |
| Coronary Care Unit of Clinical Hospital Center Bezanijska Kosa, Belgrade, Serbia | 1705 | 11 | [33] |
3.15. Heart Disease Data Set
The dataset is comprised of the Hungarian dataset (with 294 participants) provided by the Hungarian Institute of Cardiology, the Swiss dataset (with 123 participants) provided by Switzerland University Hospital, the dataset from Cleveland (with 303 participants) provided by the Cleveland Clinic Foundation, and the Long Beach VA dataset (with 200 participants) provided by the VA Medical Center, Long Beach, California, USA. Data from these four resources were combined into a new dataset, and incomplete entries were removed. The dataset contains 822 cases including 453 patients diagnosed with CAD and 369 cases without CAD symptoms, 642 men and 180 women aged from 28 to 77 years.
3.16. PhysioNet/Computing in Cardiology (CinC) Challenge
The PhysioNet web resource for complex physiological signals [63, 64] provides access to a collection of recorded physiological signals. PhysioNet jointly with the Computing in Cardiology conference [65] hosts a series of challenges, inviting participants to tackle clinically interesting problems. Four papers [20, 21, 23, 43] using the datasets provided as CinC challenges data sources were included in our review.
3.17. PhysioNet/CinC Challenge 2011 Database
The CinC challenge 2011 was titled “Improving the quality of ECGs collected using mobile phones”. The dataset includes standard 12-lead ECG recordings (leads I, II, II, aVR, aVL,aVF, V1, V2, V3, V4, V5, and V6) with full diagnostic bandwidth (0.05 through 100 Hz). The leads were recorded simultaneously for a minimum of 10 seconds; each lead was sampled at 500 Hz with 16-bit resolution. ECGs collected for the challenge were reviewed independently by a group of annotators who examined each ECG and assigned it a signal quality letter grade from A (excellent) to F (unacceptable). The average grade was calculated in each case, and each record was assigned to one of three groups: acceptable, indeterminate, unacceptable. The collection of 1500 twelve-lead ECGs, each being 10 seconds long, are available and split into training and test sets.
3.18. Physionet/CinC Challenge 2015 Database
The CinC Challenge 2015 was titled Reducing False Arrhythmia Alarms in the ICU. The dataset provides ECG, ABP (arterial blood pressure), PPG (photoplethysmogram) and respiratory data from intensive care with arrhythmia alarms for five life-threatening arrhythmia types: asystole, extreme bradycardia, extreme tachycardia, ventricular tachycardia, and ventricular flutter or fibrillation. The data consists of 750 records for the training set and 500 records for the unrevealed test set. Both in the training and test set, half of the records are 5 min long and the other half contains an additional 30 s after the alarm. In every record, the alarm occurs at 5 min from the beginning of the record.
3.19. PhysioNet/CinC Challenge 2016 database
The CinC Challenge 2016 was aimed at the development of heart sounds classification algorithms. The sound recordings were collected in either a clinical or non-clinical (such as in-home visits) environment, from both healthy subjects and pathological patients. The Challenge training set consists of a total of 3,126 heart sound recordings lasting from 5 seconds to over 120 seconds.
3.20. MIT-BIH Arrhythmia Database (MITDB)
MIT-BIH Arrhythmia Database [66, 67] was completed and its distribution started in 1980. This is also provided by the PhysioNet web resource. The database contains ECG recordings collected at Boston's Beth Israel Hospital. The MIT-BIH Arrhythmia Database contains 48 fragments of half-hour ECG recordings obtained from 47 subjects studied by the BIH Arrhythmia Laboratory between 1975 and 1979.
3.21. MESA (Multi-Ethnic Study of Atherosclerosis)
The Multi-Ethnic Study of Atherosclerosis (MESA) is a study of the characteristics of subclinical cardiovascular disease (disease detected non-invasively before it produces clinical signs and symptoms) and the risk factors that predict progression to clinically overt cardiovascular disease or progression of the subclinical disease [68, 69]. The Multi-Ethnic Study of Atherosclerosis started in 2000 and included 6814 asymptomatic participants aged 45-84. The data includes Traditional Risk Factors, Demographics, Atherosclerotic markers, Magnetic Resonance Imaging (MRI) markers, Lab Biomarkers, etc. There are 735 features in total.
3.22. Unpublished Datasets / Not Publicly Accessible Datasets
Eighteen papers used datasets not available in public repositories. Table 7 provides those datasets, the number of features, and the number of attributes for each of them. The biggest dataset in terms of the number of samples is the dataset presented in the Clinical Practice Research Datalink. CPRD website [70] says that CPRD collects de-identified patient data from a network of GP practices across the UK. Primary care data in combination with other health-related data constitute a representative UK population health dataset. The data include over 35 million patients. However, the study reported a subset of 383 592 records, and 378 256 of them met the criteria of the work and were included. All the remaining datasets contain less than 62 000 samples.
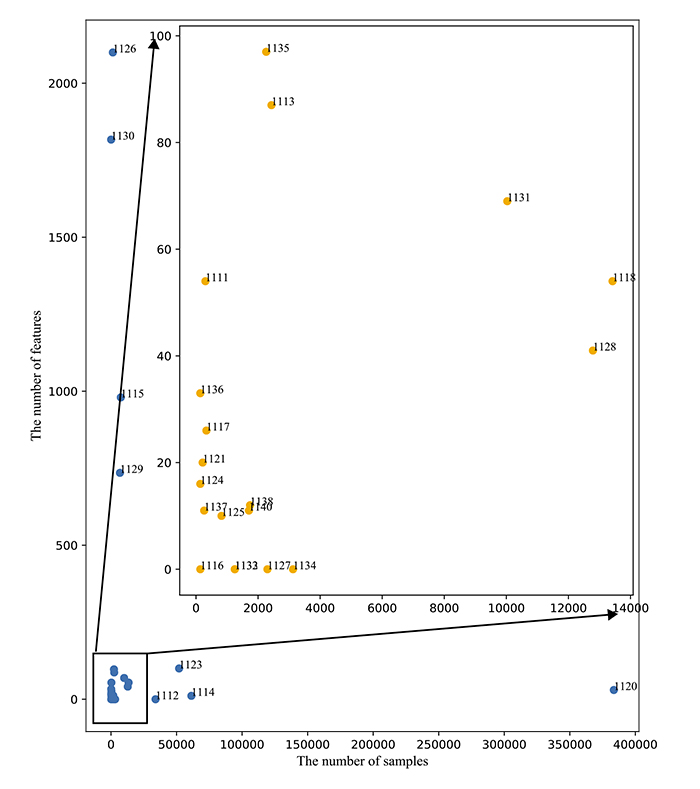
The biggest amount of features comprises 2100 attributes [41]. However, 22 of 27 (81%) works used datasets with less than 100 features.
Fig. (3) is a plot that shows the destitution of the datasets with the number of samples as the X-axis and the number of features as the Y-axis. Most datasets (18 of 27) are located in a square limited by 14 000 samples and 100 features.
3.23. Evaluation of Algorithms
The papers reviewed employed different metrics to evaluate their results. The full list of metrics comprises 26 items. Table 8 provides the most commonly used metrics observed in the papers reviewed. A comprehensive table with all metrics is provided in Supplement 1.
Table 8.
| Metric | Papers | N |
|---|---|---|
| Sensitivity / Recall / TPR | [16, 18, 19, 21, 24, 26, 28, 30, 33, 34, 36-39, 41, 42] | 18 |
| Specificity / TNR | [16, 18, 19, 21, 24, 26, 28, 30, 32-34, 36-39, 41, 42] | 17 |
| AUC ROC | [18, 19, 24-26, 28-32, 33-36, 39, 42] | 16 |
| Accuracy | [13, 18, 19, 23, 24, 27, 28, 33, 36, 37, 38, 41, 43] | 13 |
| Precision / PPV | [18, 21, 24, 28, 30, 37] | 6 |
| F-score / F1 / F-measure | [21, 28, 33, 37-39] | 6 |
Not only the metrics, but also the number of metrics each paper used was reviewed in our study (Table 9). Fourteen works engaged less than four different metrics and eleven papers considered five or more different evaluation metrics. Below, we give an overview of the frequent metrics we identified and how they were calculated.
The most basic approach to evaluating classification results is a confusion matrix (Table 10). To build such a matrix, every classified example must be labeled as one of the following types: True Positive (TP) examples are classified as positive and are actually positive (right classification); True Negative (TN) examples are classified as negative and are actually negative (right classification); False Positive (FP) examples are classified as positive but are actually negative (type I error); False Negative (FN) examples are classified as negative but are actually positive (type II error). Most of the considered examples are based on the confutation matrix.
Accuracy is the most common and easy to understand evaluation metric. Accuracy was used to measure the classification performance in 13 of 27 works (66%) included in this review. It is the ratio of all correct predictions to the total amount of all predicted samples. In many cases, accuracy is not a very helpful metric.
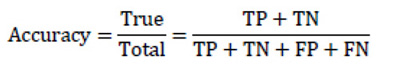 |
(1) |
To get a more indicated and helpful evaluations for classifications, Precision and Recall algorithms are used.
Precision is the proportion of predicted positive outcomes that are really correct positive results to all positive predicted samples. Precision gives an answer to the question: of all the samples we classified as true, how many are actually true? This metric was applied in six considered papers.
 |
(2) |
The Recallis the ratio of obtained relevant instances (true positive outcomes) and the total amount of relevant samples. It shows how many of all actual positive examples were classified correctly. The higher the Recall, the fewer the positive examples missed in the classification.
 |
(3) |
Both metrics are connected to each other, a higher level of Precision may be obtained by decreasing recall and vice versa. Since that, separating using neither Precision nor recall is a good evaluator of a classification algorithm. In order to combine both metrics into one, the F-Score is used.
| – | Actual | ||
|---|---|---|---|
| Positive | Negative | ||
| Predictive | Positive | TP | FP (Type I error) |
| Negative | FN (Type II error) | TN | |
F-Score (F-measure or F1 score) is the weighted harmonic mean of precision and recall. This metric demonstrates how many cases the model predicts correctly, and how many true instances the model does not miss. F-score appears in six papers considered.
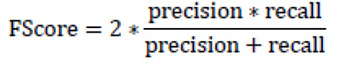 |
(4) |

Another informative and very common metric is Area Under the Receiver Operating Characteristic Curve (AUC ROC) [72]. The curve is a graph showing the performance of the classification model and it plots two parameters: True Positive Rate (TPR) and False Positive Rate (FPR). It summarizes the trade-off between TPR and FPR using all different classification thresholds. The big advantage of that metric is that AUC evaluates models independently from the threshold. AUC ROC is a common metric among the considered papers and it was used in 16 works.
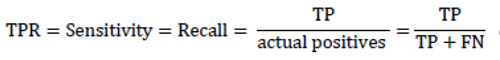 |
(5) |
As a matter of fact, TPR completely equals to recall and sensitivity and shows the proportion of positive examples that are correctly classified to all actual positive examples. In its turn, FPR is the proportion of actual negative examples that are mistakenly classified as positive (FP), to all actual negative ones. The higher the FPR, the more negative examples are classified wrong.
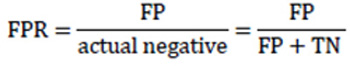 |
(6) |
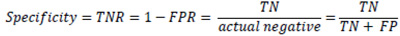 |
(7) |
In some sources, another metric is called Specificity or True negative rate (TNR). TNR measures the proportion of actual negative examples that are correctly classified as negative. This is the opposite metric to the FPR and is often used coupled with sensitivity or TPR. 17 papers cited this metric.
4. DISCUSSION
We systematically reviewed 27 papers describing machine learning algorithms applied for the decision support in cardiology. The diversity and maturity machine learning methods presented in these papers allow making conclusions on what the state of the art is and what future directions of the ML in cardiology can be. In this section, we discuss findings of the review, including aims and outcomes, ML methods, datasets, and evaluation metrics.
4.1. Aims and Outcomes
All observed papers deal with classification. Nonetheless, ML methods can handle regression and clusterization tasks as well, but we did not reveal such works. Many of the studies deal with binary classification only and predict mortality or diagnose CAD in a binary way. We assume that there is room for improvement here, and aims for ML-based systems can be given in a more sophisticated manner.
4.2. Methods
Our study revealed more than ten different ML methods implemented in the observed studies. This is a good variety, but all methods are related to classification, not regression. Moreover, all methods belong only to supervised learning, and none of the reports are about unsupervised learning or clustering.
None of the papers observed in our review reported the implementation of the RL approach. Extra search for RL implementations in cardiology on PubMed produced no paper that could be included. Kipp et al. [73] also report the fact that “Application of reinforcement learning to health care and cardiology thus far has been scarce”.
We associate this with the complexity of RL algorithms implementation and the lack of suitable data. The data should be not only sufficient, but it needs to be presented in the appropriate form. To get such data representation is not a trivial task. Nonetheless, the application of RL in medicine and cardiology, in particular, is very promising and needs a closer look.
Some of the observed papers implement several methods independently and compare results, which we consider a good practice since there is no way to be sure which method has a better performance in every particular task. Several works implemented ensembles. Tree-based ensembles are the most common methods in our research, but all the methods are well-known and were used in many different tasks. However, there is a lack of more sophisticated and innovative methods such as, for example, XGBoost [74], an ensemble method that has empirically proven to be a highly effective approach by gaining the best results in numerous machine learning competitions [75]. Deep neural networks are also poorly represented.

A broad variety of different network architectures was not covered by the papers. State-of-the-art algorithms remained outside the reviewed works. The implementation of advanced ML algorithms in the field of cardiology is still an underdeveloped niche.
4.3. Datasets
Repositories containing the datasets report about hundreds of studies referring to them. Nevertheless, only 7 of 27 works (26%) in our review employed publicly available datasets. That might be explained as a commitment to solving a particular real-life task with particular real data collected in the environment that the solution is supposed to work in later. At the same time, the use of data that is hardly available for other researchers leads to the lack of reproducibility and comparability of the results.
When developing a system, it is good to have data of the same structure and from the same source as the data that will be used in the system. In contrast, for the works given in order to evaluate applications of a certain method to the specific task as well as for works aimed to show improvement in existing algorithms or presenting new algorithms, it is meaningful to employ well-known and accessible datasets. This gives the opportunity to compare results and see real advantages or disadvantages of the proposed algorithm. We also suggest that publication of de-identified data along with the research papers will have a positive impact on future developments.
4.4. Evaluation
We identified 28 different metrics for a classification task. This variety of metrics makes it difficult to compare and understand research results. The metrics show incomparable aspects of algorithm efficiency. This way, selecting a metric is an important task that should be done at the beginning of developing an ML system. It is necessary to decide which is more important: to classify some healthy patients as ill and start treatment they do not need to misclassify healthy, but omit some ill patients and do not give them the treatment they need. The decision depends on many factors and should be made for every particular task.
The second issue here is the difference in the names of metrics that are calculated in the same way but come from different domains. Thus, recall and sensitivity are the same function, but the first term is mostly used in information retrieval and the second one is more typical for statistics and medical tests. Moreover, this function sometimes might be called as TRR (true positive rate) or 1 – FNR (false-negative rate). That is true not only for recall/sensitivity but also for some other metrics. It makes interpreting and comparing results more complicated.
The third issue of algorithm evaluation is a decrease in model performance due to the difference between training and real data. Li et al. [43] evaluated an algorithm on real unseen data and discovered a lower performance score. This is a common problem for machine learning algorithm evaluation. First of all, it means that we cannot directly compare the efficiency of two algorithms or systems if they were evaluated on different datasets.
4.5. Future Directions
Based on the obtained results of our review, we suppose that, in the nearest future, systems employing deep neural networks will actively spread in the domain along with a growing variety of tasks and applications of ML systems in cardiology. We also expect works reporting on another very promising branch of ML: Reinforcement Learning [76].
In addition, we assume that creating a pool of openly accessible datasets related to cardiological issues will open new opportunities for researchers and result in a big positive impact on the field.
CONCLUSION
In this systematic review, we identified studies where machine learning algorithms were applied in the domain of cardiology and examined four aspects: aims, ML methods, datasets, and evaluation metrics. We showed that a broad variety of methods are applied in cardiology, but all methods belong to a group of supervised learning classification methods; more often than not, researchers use unpublished, hardly available data; different studies aimed at similar tasks and engaging similar methods could not easily compare to each other (Fig. 4).
We hope that this systematic review will be a helpful tool for researchers who are developing machine learning based systems in medicine and particularly in cardiology.
LIMITATIONS
The paper covers studies published between 2013-2017. Only one literature database, PUBMED, was used in the research. This paper evaluated the included papers on the basis of only the four questions mentioned, however, additional aspects, such as data preprocessing, feature selection, dimensionality reduction, content, and structure of input data should also be analyzed in future works. Electrocardiogram (ECG) signal processing was not considered in this review, however, there can also be some valuable results in the field of machine learning. We could not give a quantitative estimate for the algorithms due to the heterogeneity of the metrics used in different studies.
LIST OF ABBREVIATIONS
| ABP | = Arterial Blood Pressure |
| AI | = Artificial Intelligence |
| ANN | = Artificial Neural Networks |
| ANS | = Autonomic Nervous System |
| AUC ROC | = Area Under the Receiver Operating Characteristic Curve |
| CDSS | = Clinical Decision Support Systems |
| CVD | = Cardiovascular Diseases |
| ECG | = Electrocardiogram |
| FN | = False Negative |
| FNR | = False Negative Rate |
| FP | = False Positive |
| FPR | = False Positive Rate |
| GBDT | = Gradient Boosted Decision Trees |
| K-NN | = K Nearest Neighbor |
| LR | = Logistic Regression |
| ML | = Machine Learning |
| MLP | = Multi-layer Perceptron |
| MRI | = Magnetic Resonance Imaging |
| NB | = Naïve Bayes |
| NLP | = Natural Language Processing |
| PPG | = Photoplethysmogram |
| RF | = Random Forest |
| SVM | = Support Vector Machines |
| TN | = True Negative |
| TNR | = True Negative Rate |
| TP | = True Positive |
| TPR | = True Positive Rate |
AUTHORS' CONTRIBUTIONS
AD was responsible for data collection, analysis and manuscript drafting. MG was responsible for the manuscript writing. GP was responsible for the methodological part of the study.
CONSENT FOR PUBLICATION
Not applicable.
STANDARD OF REPORTING
PRISMA Guideline and methodology were followed.
FUNDING
This work was financially supported by the Government of the Russian Federation through the ITMO fellowship and professorship program. This work was supported by a Russian Fund for Basic research 18-37-20002.
CONFLICT OF INTEREST
The authors declare no conflict of interest, financial or otherwise.
ACKNOWLEDGEMENTS
Declared none.
SUPPLEMENTARY MATERIAL
Supplementary material is available on the publishers web site along with the published article.

